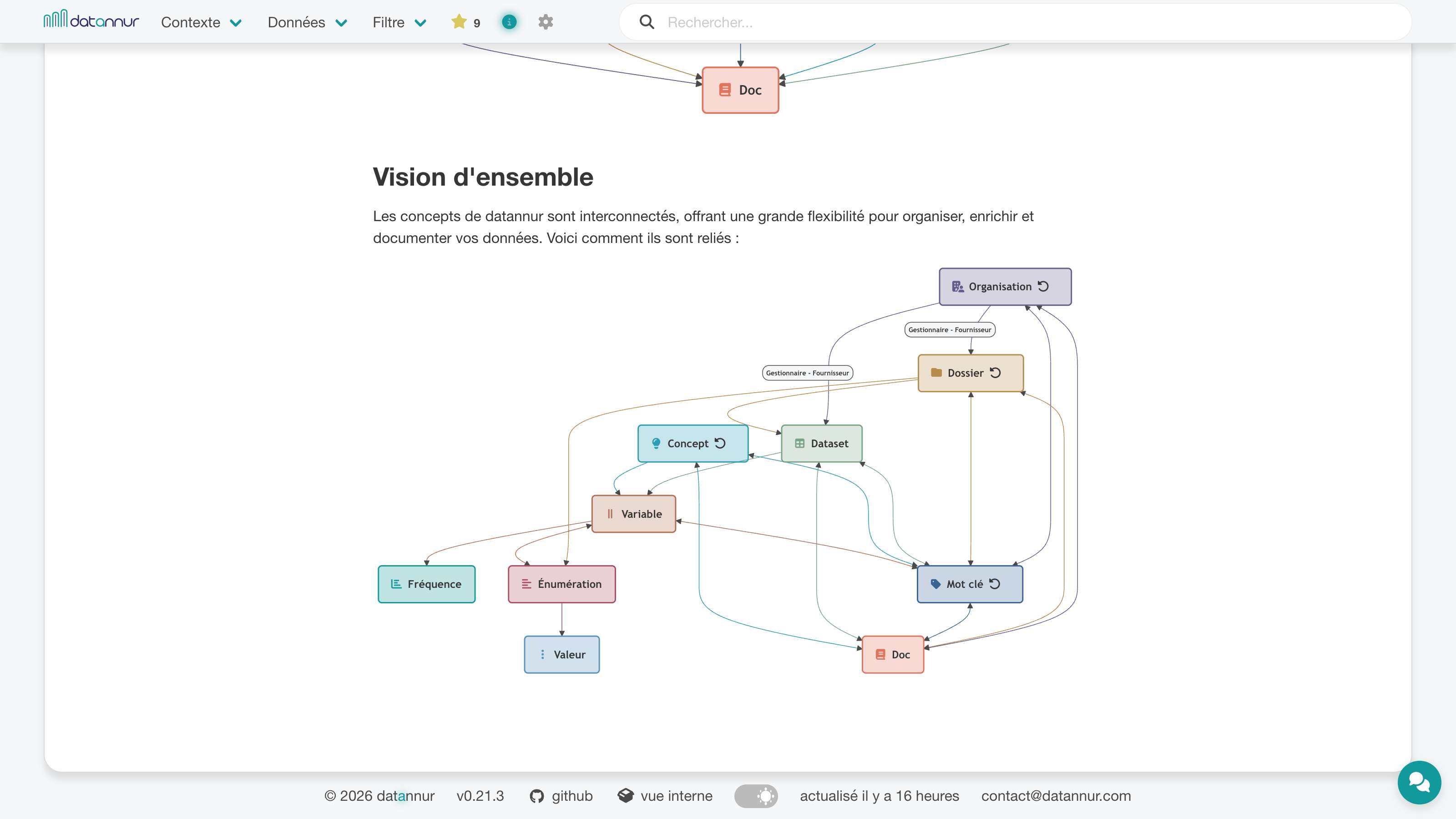
datannur réunit dans une même interface les fonctions essentielles d’un catalogue de données : navigation, documentation, exploration et exploitation des métadonnées. L’outil permet de retrouver les jeux de données, de comprendre leur structure, d’explorer leurs dépendances et d’en suivre l’évolution dans le temps.
L’objectif n’est pas seulement de stocker de l’information, mais de rendre les données plus lisibles, plus exploitables et plus simples à gouverner au quotidien.
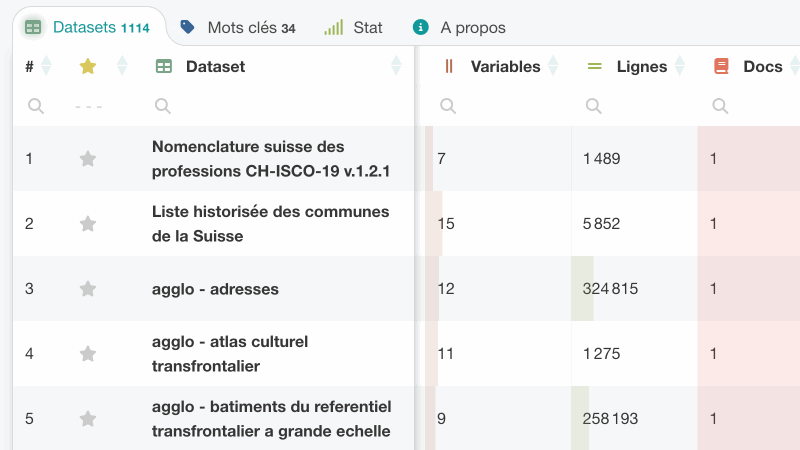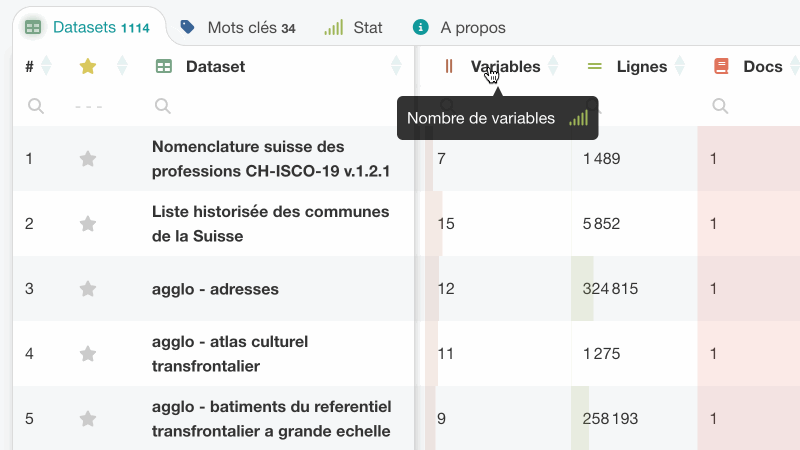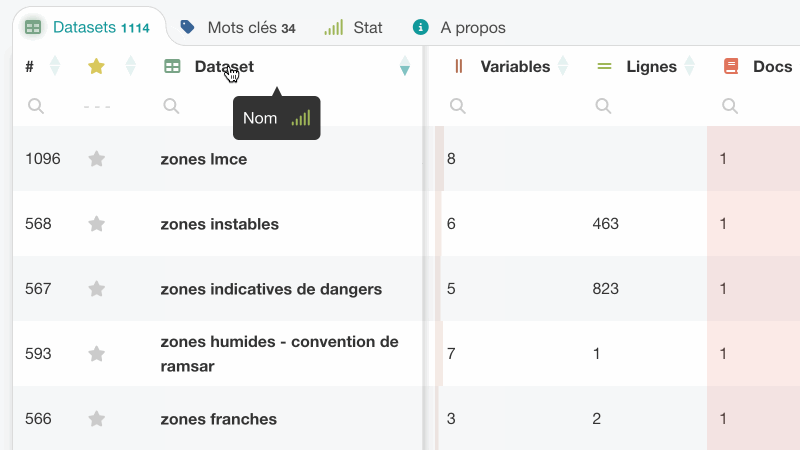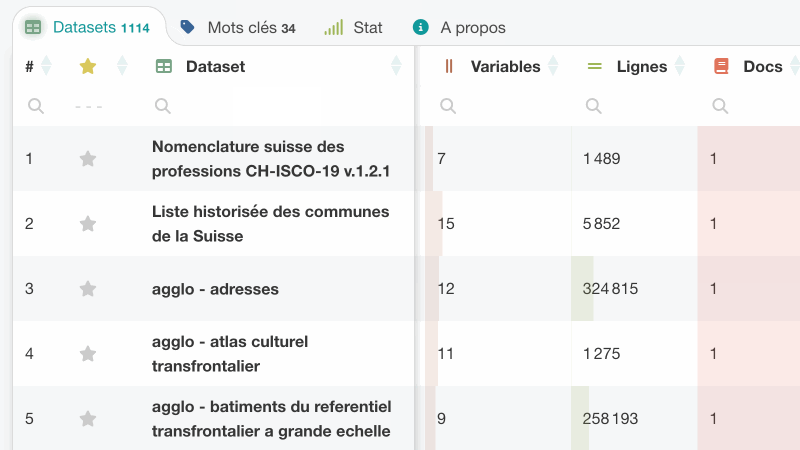
datannur permet de parcourir le catalogue de plusieurs façons complémentaires. L’arborescence donne une vue structurée des organisations, dossiers, jeux de données, variables et documents, tandis que la recherche et les filtres donnent un accès direct à l’information pertinente.
Cette navigation multiple rend le catalogue utilisable aussi bien pour une exploration globale que pour des besoins ciblés : retrouver un jeu de données, identifier une variable, repérer un responsable ou naviguer dans un ensemble documentaire lié.
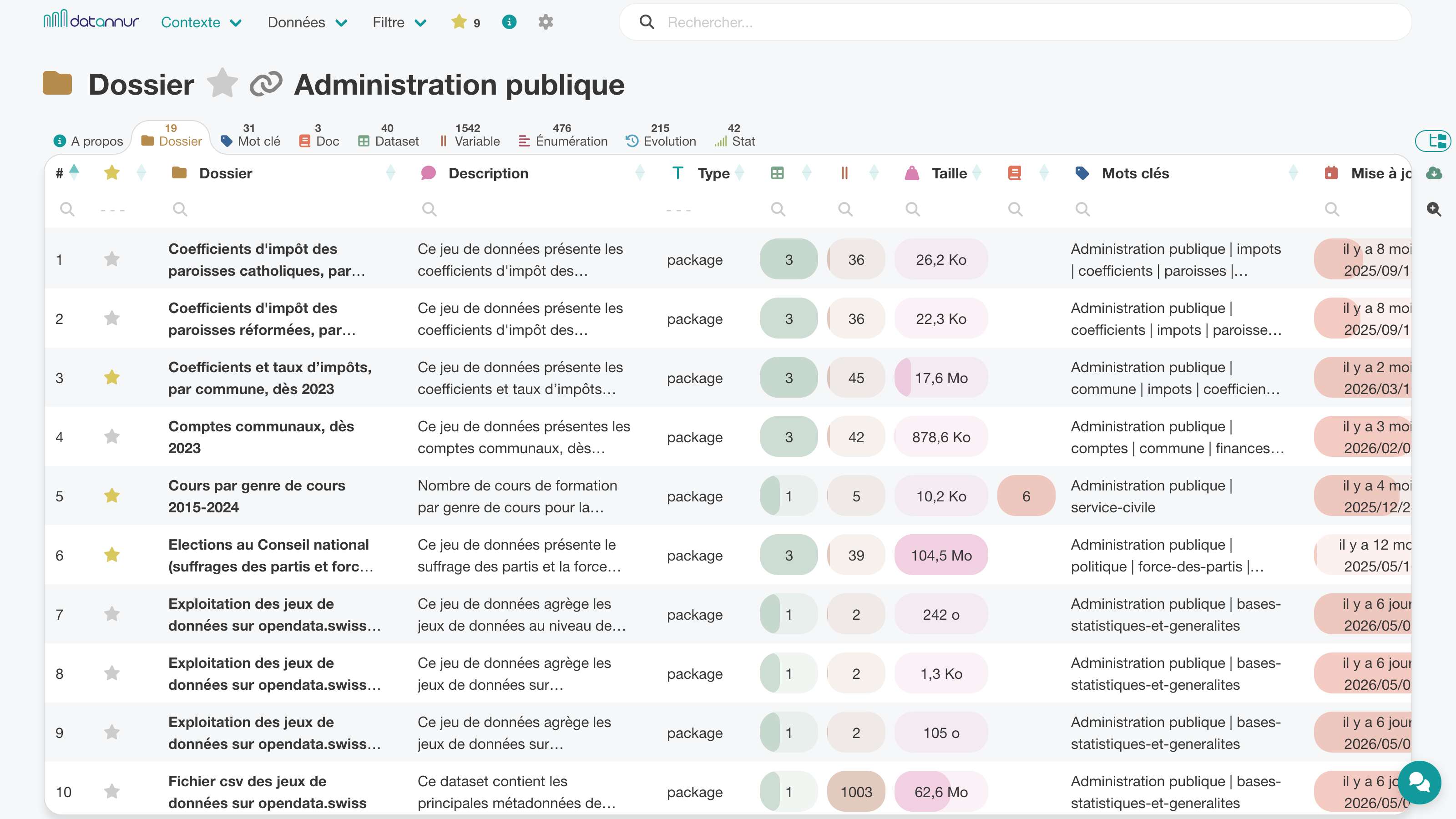
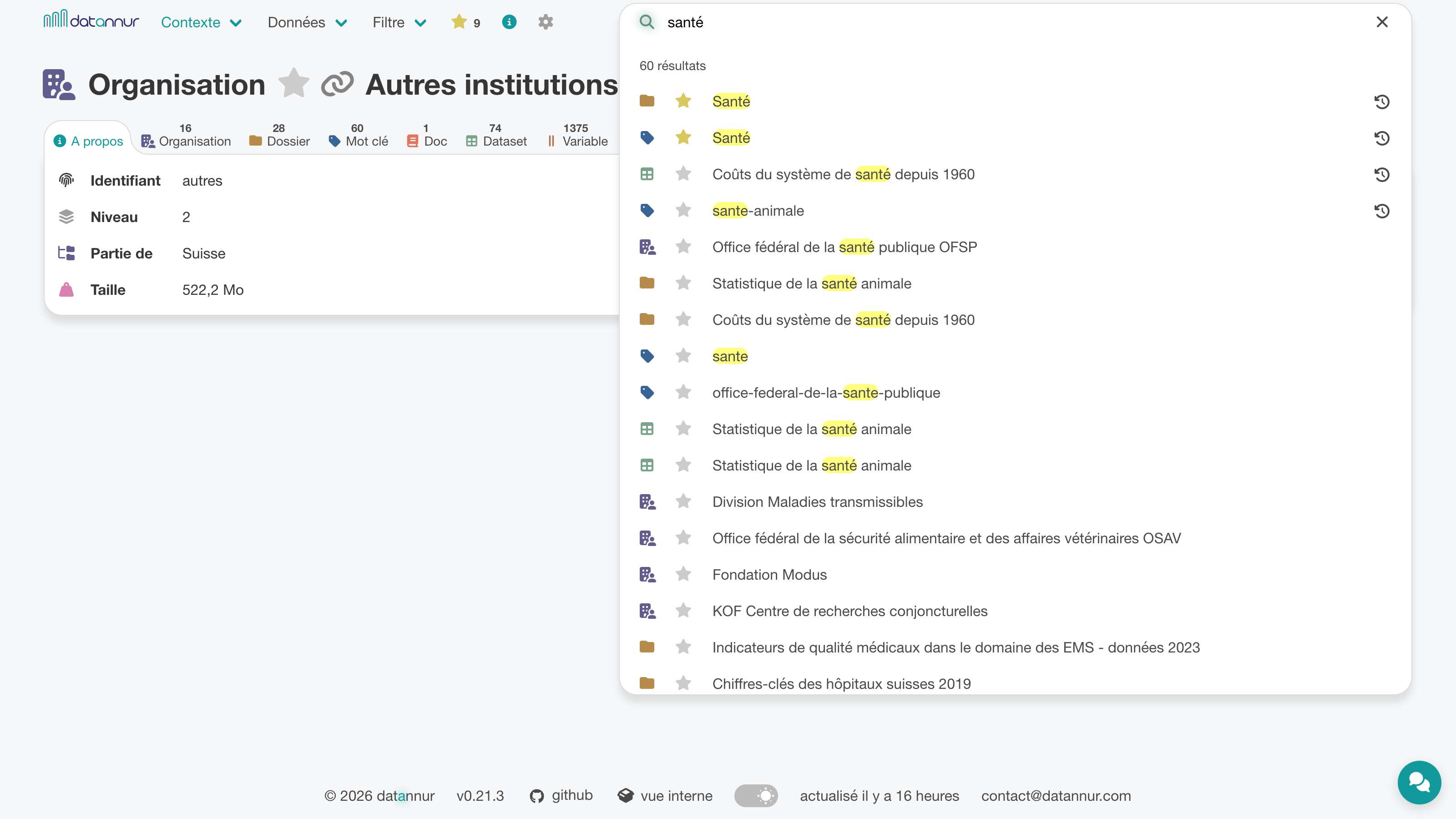
La barre de recherche permet de retrouver rapidement les éléments les plus pertinents à partir des termes saisis. Une page dédiée affiche les résultats de manière claire, avec un accès direct aux recherches récentes.
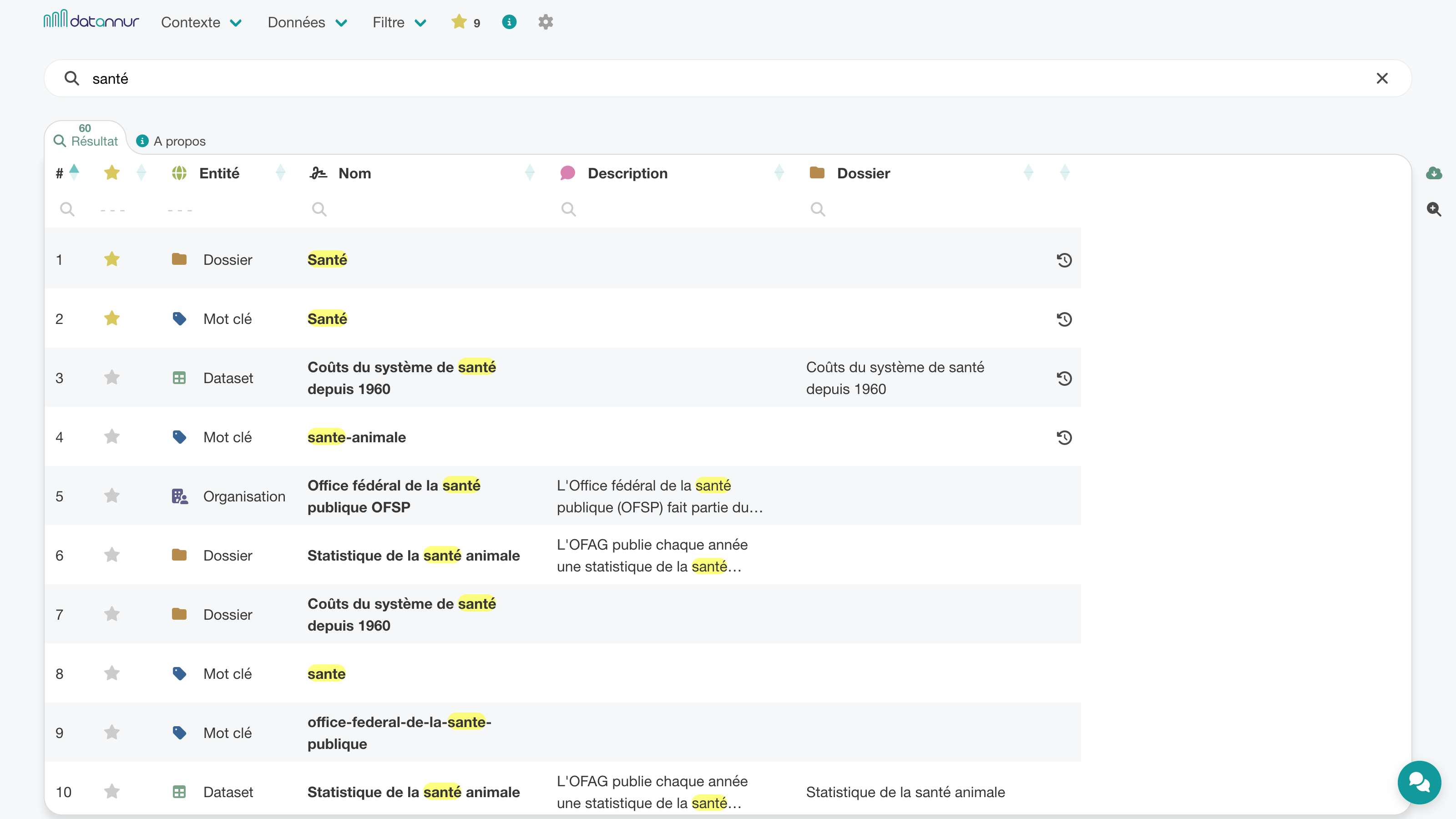
Chaque tableau propose des filtres par colonne pour affiner les résultats de façon plus précise que par la recherche globale. Plusieurs filtres peuvent être combinés pour isoler un sous-ensemble pertinent en quelques gestes. Les filtres prennent en charge différents types de conditions selon la nature des colonnes.
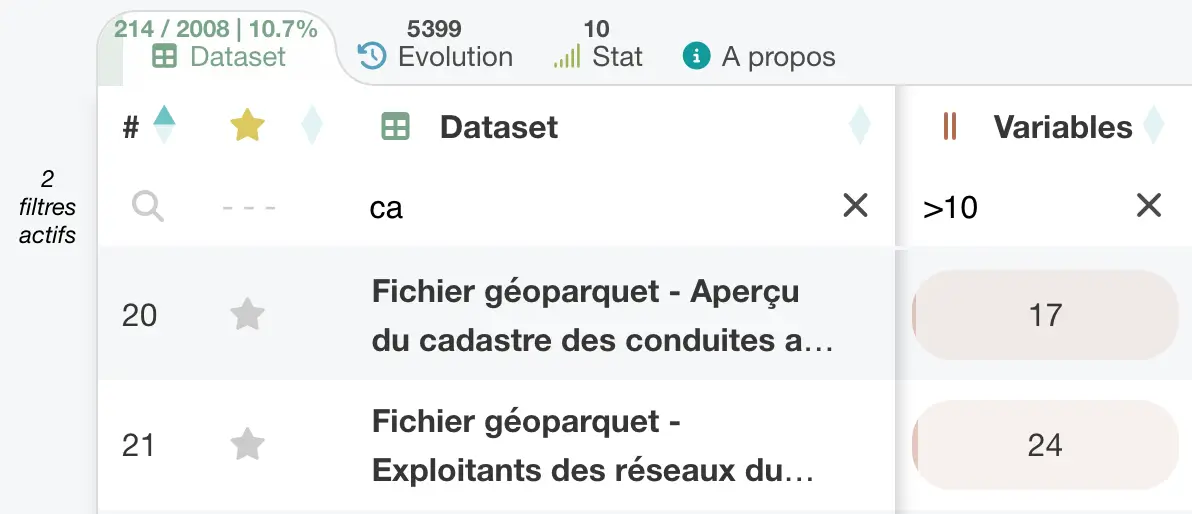
Un filtre global permet également d’inclure ou d’exclure certaines catégories de datasets à l’échelle du catalogue, par exemple selon leur statut d’ouverture ou leur niveau de traitement.

Les tableaux peuvent être triés en ordre ascendant ou descendant à partir de chaque colonne. Ce tri se combine naturellement avec les filtres pour faciliter l’exploration et l’analyse des données.
datannur s’appuie sur une structure arborescente pour organiser les organisations, les dossiers et les mots clés. Chaque élément peut contenir des sous-éléments sur plusieurs niveaux, ce qui permet de représenter fidèlement des organisations complexes.
Chaque nœud de l’arborescence dispose de sa propre page et agit comme un sous-ensemble du catalogue. Il est ainsi possible d’explorer à la fois son contenu, son contexte, et les datasets qui lui sont rattachés. Combinée au tri et aux filtres, cette structure offre une navigation à la fois simple et puissante.
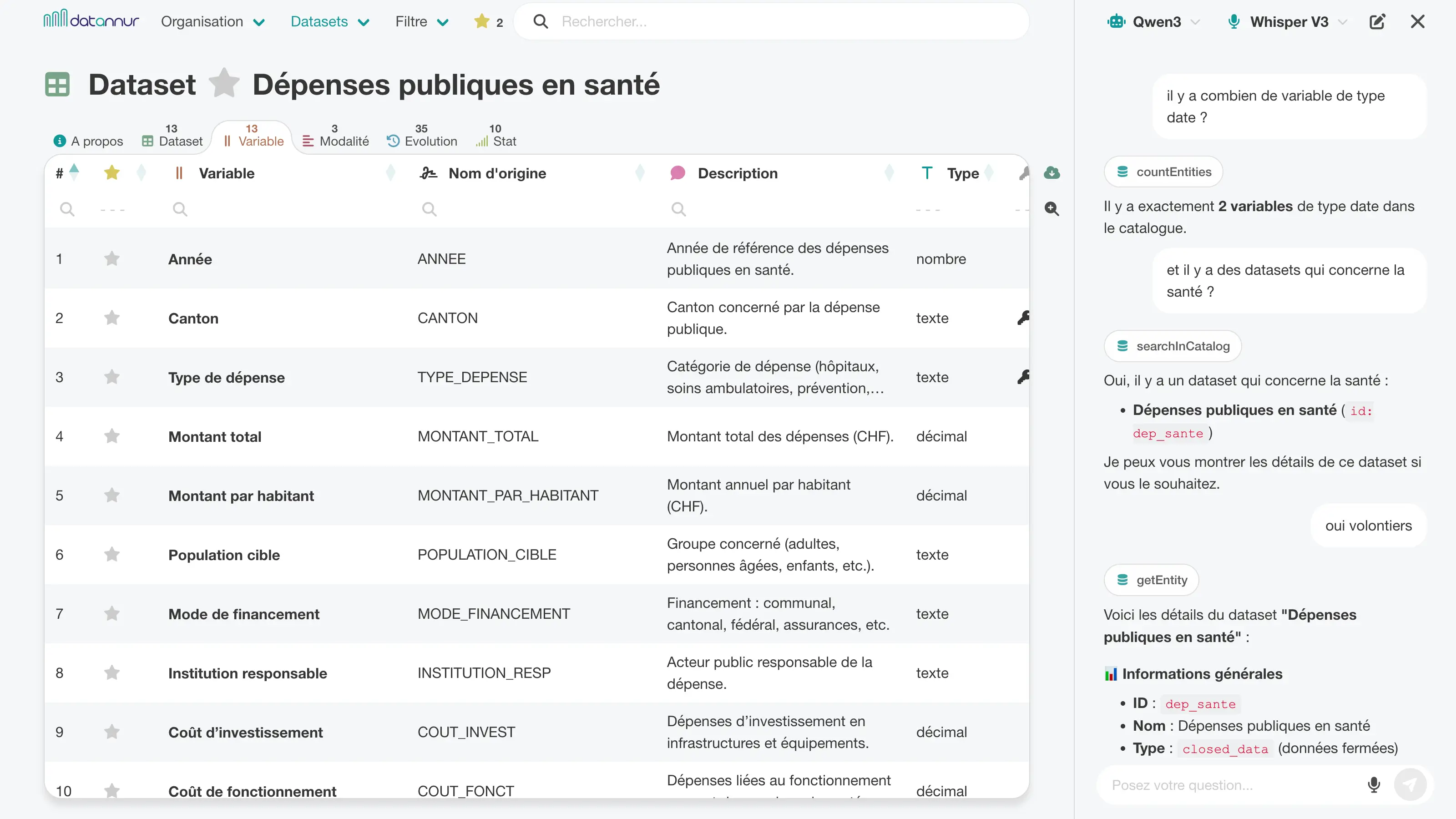
Une barre latérale de chat permet d’explorer le catalogue en langage naturel. L’assistant peut répondre à des questions sur les métadonnées, retrouver des éléments pertinents et naviguer dans le catalogue en s’appuyant directement sur les informations disponibles.
Intégré à l’interface, il complète les fonctions classiques de recherche, de filtrage et d’exploration en offrant un accès plus direct et plus souple au contenu du catalogue.
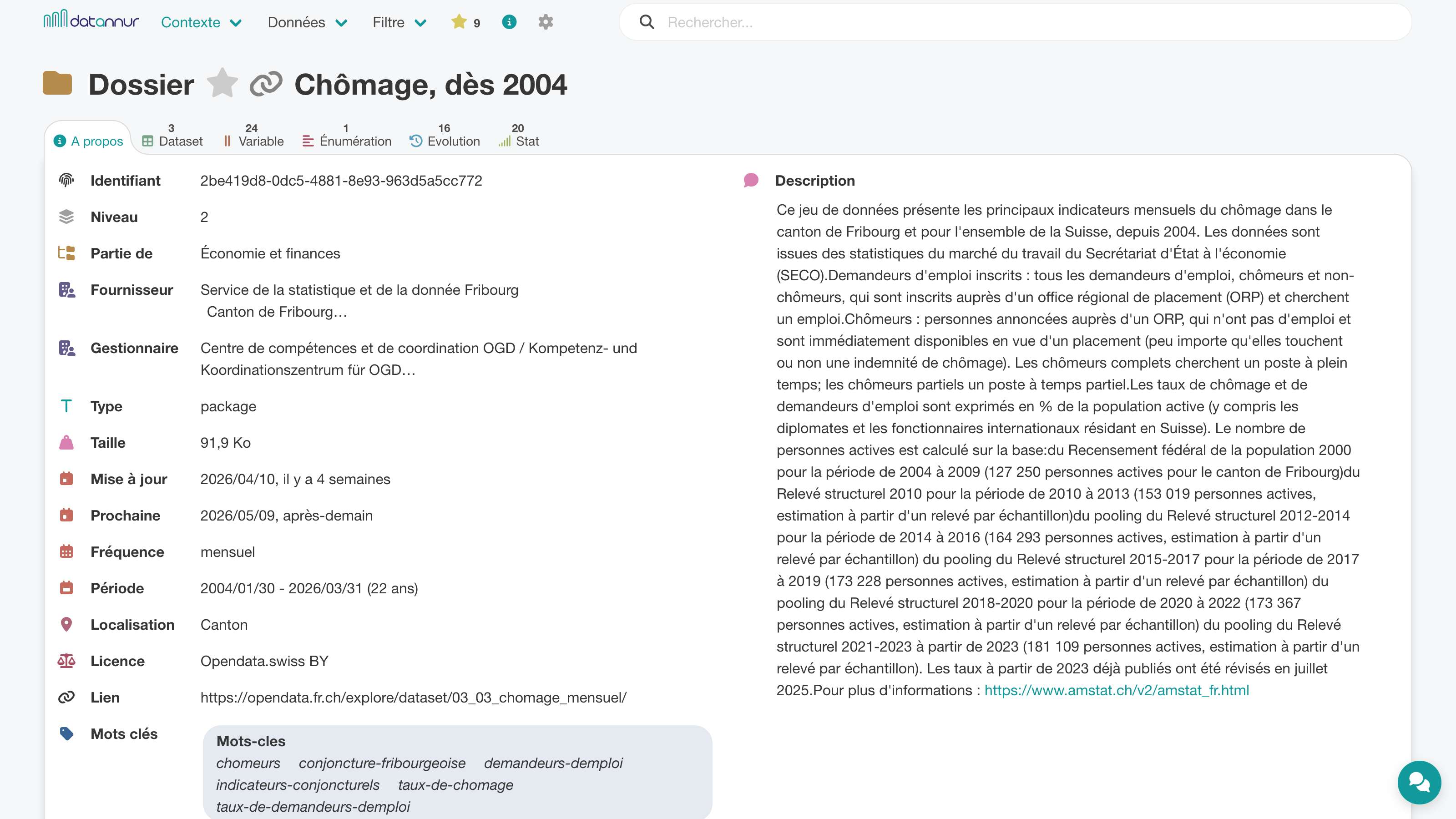
Chaque page dédiée à un élément du catalogue comporte un onglet « À propos » qui rassemble ses principales métadonnées. On y retrouve ses attributs spécifiques — par exemple une description, une date de mise à jour ou un contact — ainsi que les éléments auxquels il est rattaché, comme ses mots clés, son dossier ou ses organisations liées.
Les autres onglets donnent accès aux éléments qu’il contient ou auxquels il est associé, comme les datasets, variables, énumérations ou documents.
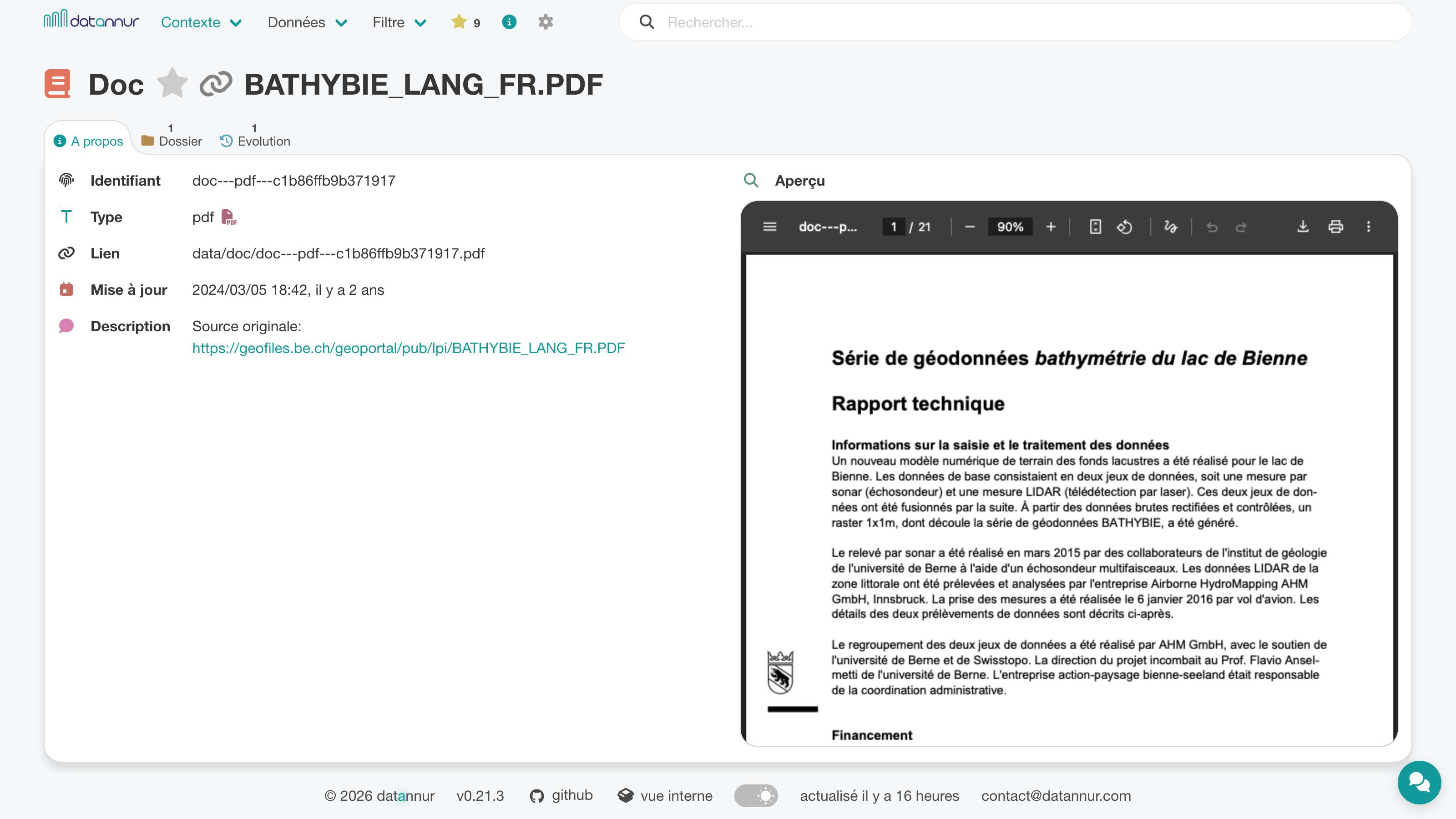
Le catalogue peut relier à ses principaux éléments une ou plusieurs documentations existantes, au format Markdown ou PDF. Il peut s’agir, par exemple, d’un README, d’une notice, d’un rapport ou d’une documentation métier déjà présente dans l’organisation. Accessibles directement depuis la page de l’élément concerné, ces documents apportent du contexte, des explications et des informations complémentaires.
datannur peut aussi embarquer un glossaire métier sous forme de concepts. Ces concepts servent à définir précisément certaines notions utilisées dans les données et à lever les ambiguïtés sur le sens exact d’une variable.
Chaque concept dispose de sa propre page, peut être organisé en hiérarchie, être enrichi par des mots clés ou des documents, et être relié aux variables concernées. Cette couche sémantique complète les métadonnées classiques en apportant un niveau d’explication plus métier.
Pour chaque variable, datannur affiche ses liens de dépendance avec les autres variables du catalogue. Il distingue les variables sources, utilisées comme entrée, et les variables dérivées, qui en dépendent.
Ces relations rendent visibles les chaînes de transformation au sein du catalogue et permettent aussi d’inférer les dépendances entre jeux de données. On peut ainsi repérer rapidement sur quels datasets un autre s’appuie, ou quels jeux de données il alimente.

L’onglet « Stat » propose une synthèse visuelle des informations disponibles dans le catalogue. Selon le type d’élément, il peut afficher aussi bien des résumés agrégés — par exemple le nombre de variables par dataset ou les mots clés associés à un dossier — que des statistiques descriptives plus fines au niveau des variables.
Pour les variables, datannur peut notamment présenter la fréquence des valeurs ainsi que des indicateurs statistiques comme le minimum, le maximum, la moyenne ou l’écart-type. Ces informations soutiennent l’exploration, le contrôle de cohérence et la compréhension rapide du contenu des données.
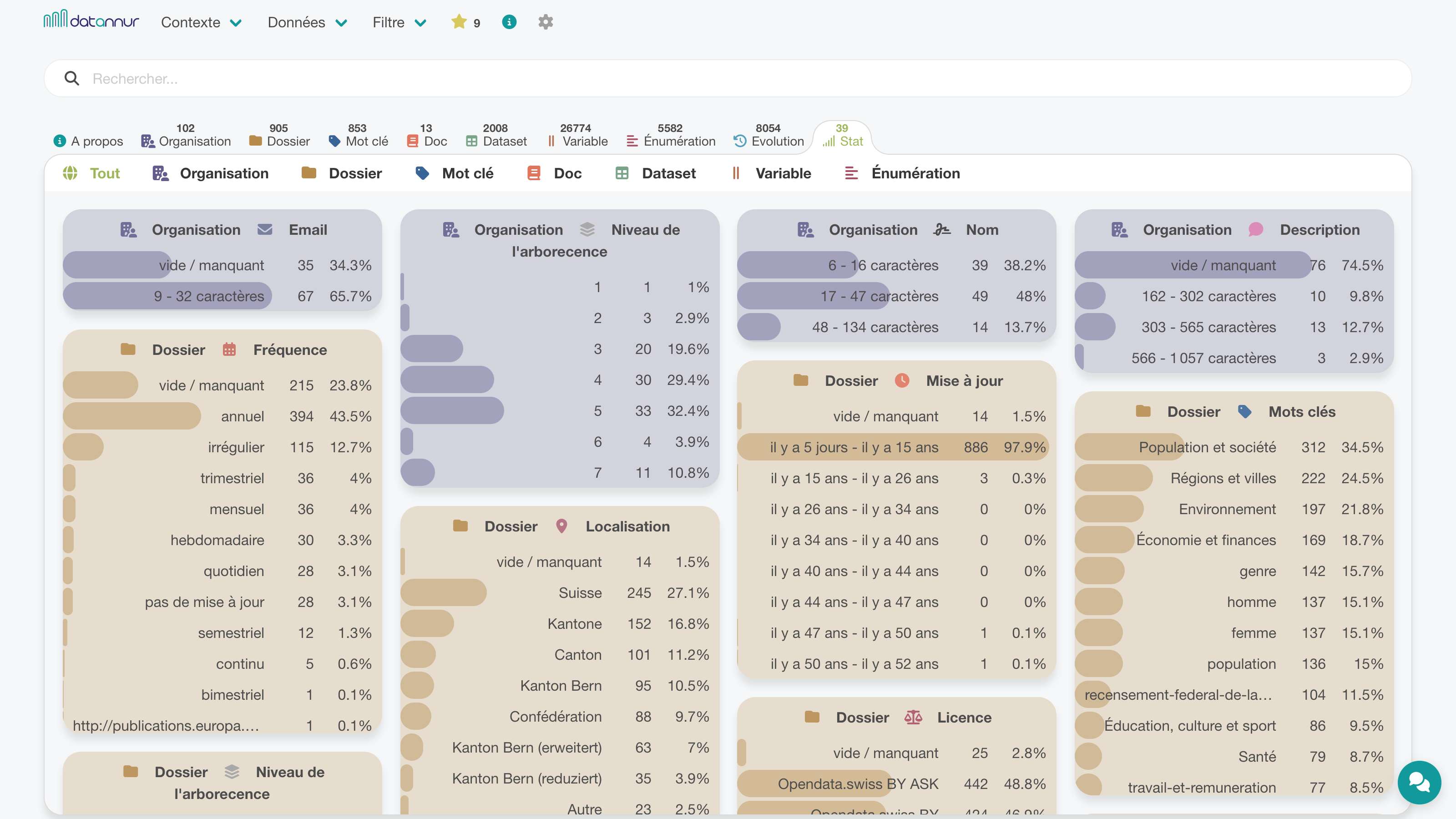
Pour les jeux de données compatibles, un onglet dédié permet d’afficher un aperçu tabulaire du contenu. Cet aperçu donne une première lecture des données et s’appuie sur les fonctions intégrées de tri et de filtrage pour parcourir les enregistrements plus efficacement.
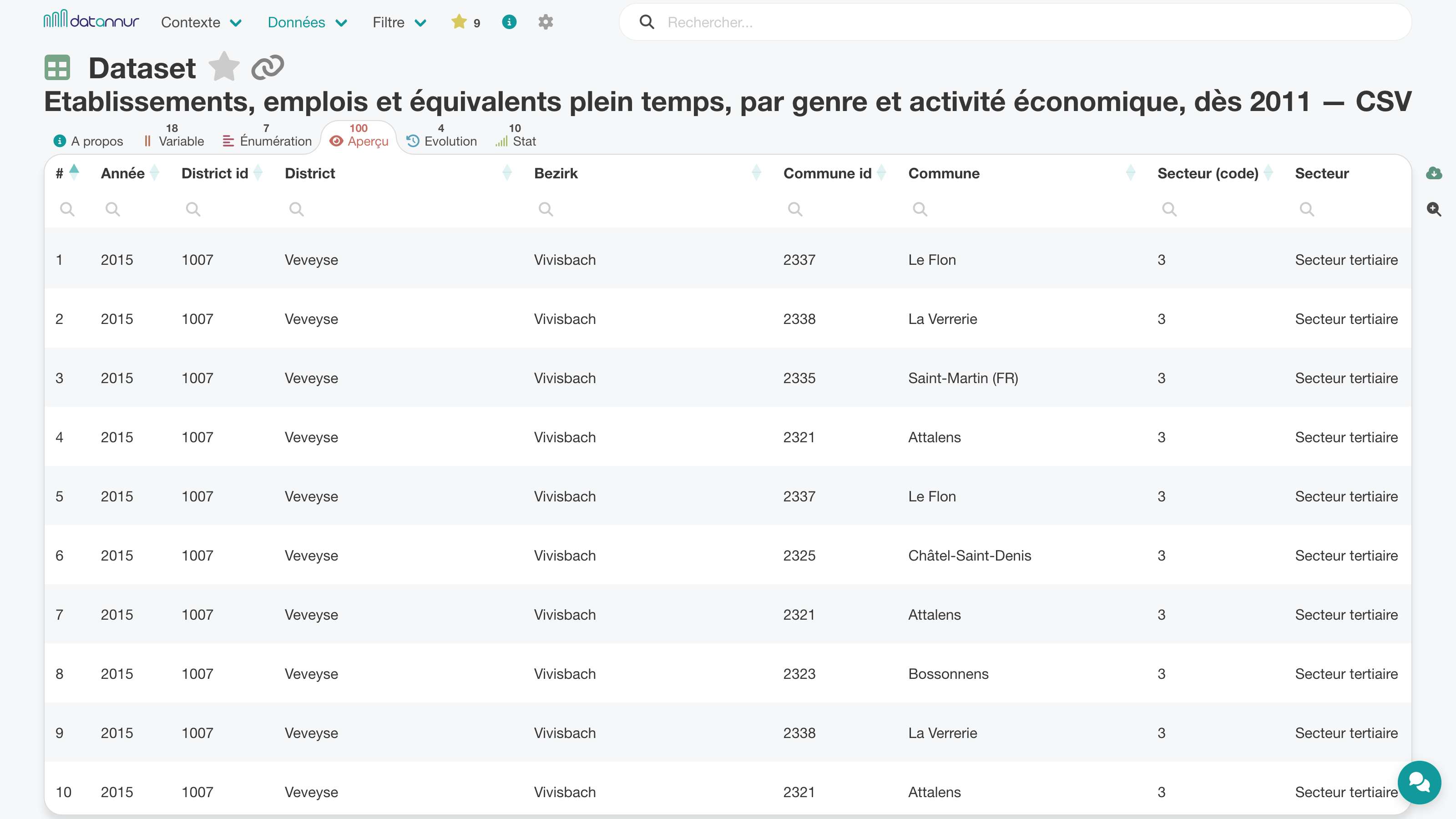
L’harmonisation des énumérations entre plusieurs jeux de données peut vite devenir fastidieuse. Pour simplifier ce travail, datannur propose un onglet qui rapproche les énumérations selon leur similarité et permet d’identifier les doublons, variantes proches ou recouvrements partiels.
Cette vue aide à repérer les écarts de libellé, à uniformiser les valeurs et à améliorer la cohérence d’ensemble du catalogue.
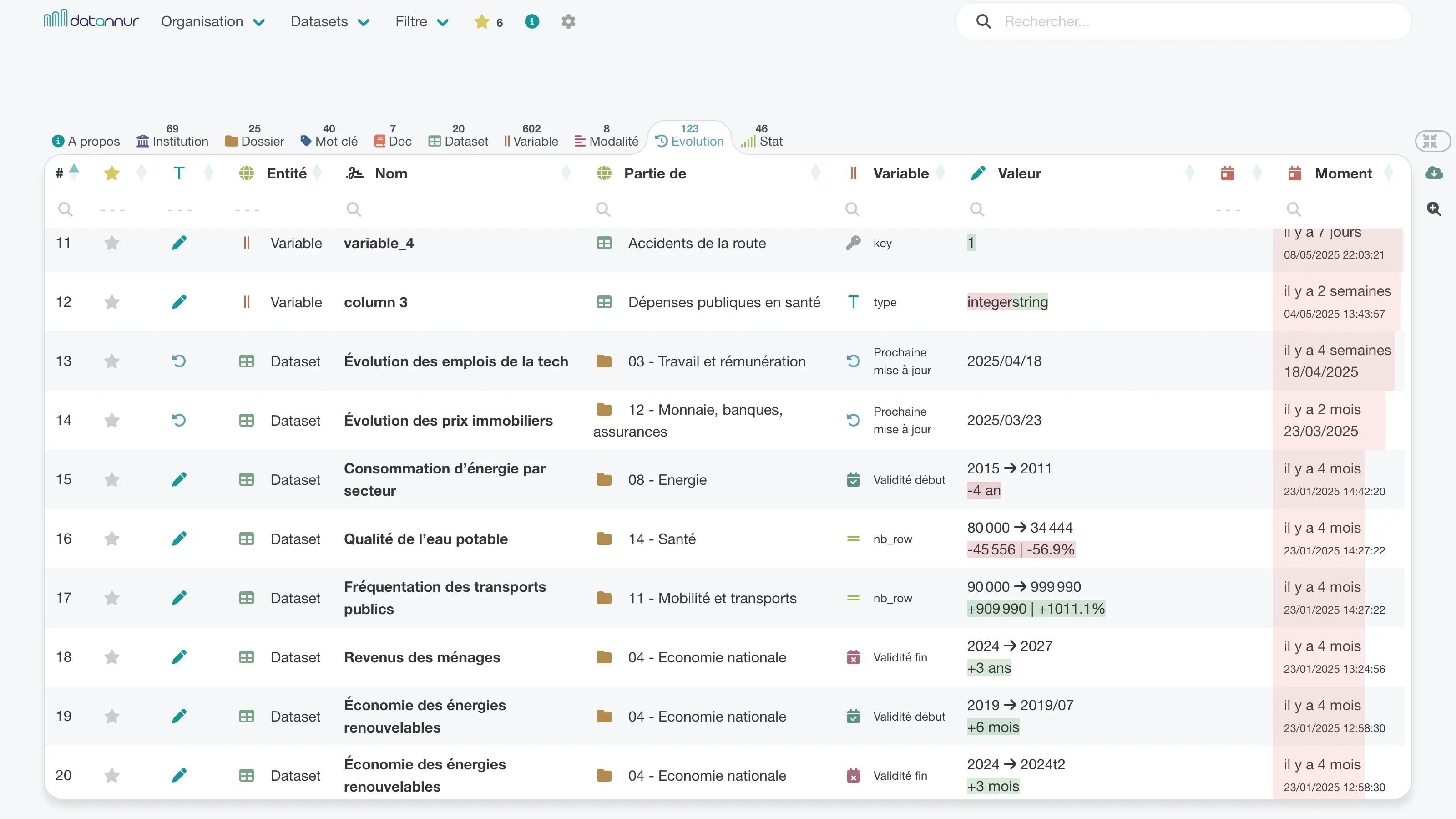
L’onglet « Évolution » permet de suivre dans le temps les changements apportés aux éléments du catalogue. Il met en évidence les ajouts, suppressions et modifications, avec leur horodatage, pour rendre l’historique des métadonnées plus lisible.
Cette vue aide à suivre les changements, contrôler la cohérence et comprendre l’évolution d’un dataset, d’une variable ou d’un autre élément du catalogue.
Les données d’utilisation sont stockées localement dans le navigateur. Le catalogue reste ainsi pleinement fonctionnel sans connexion internet, tout en conservant les favoris, recherches, journaux et préférences de l’utilisateur.
Ces éléments peuvent être exportés et importés à tout moment, ce qui facilite la continuité d’usage d’un poste à l’autre ou dans le temps.
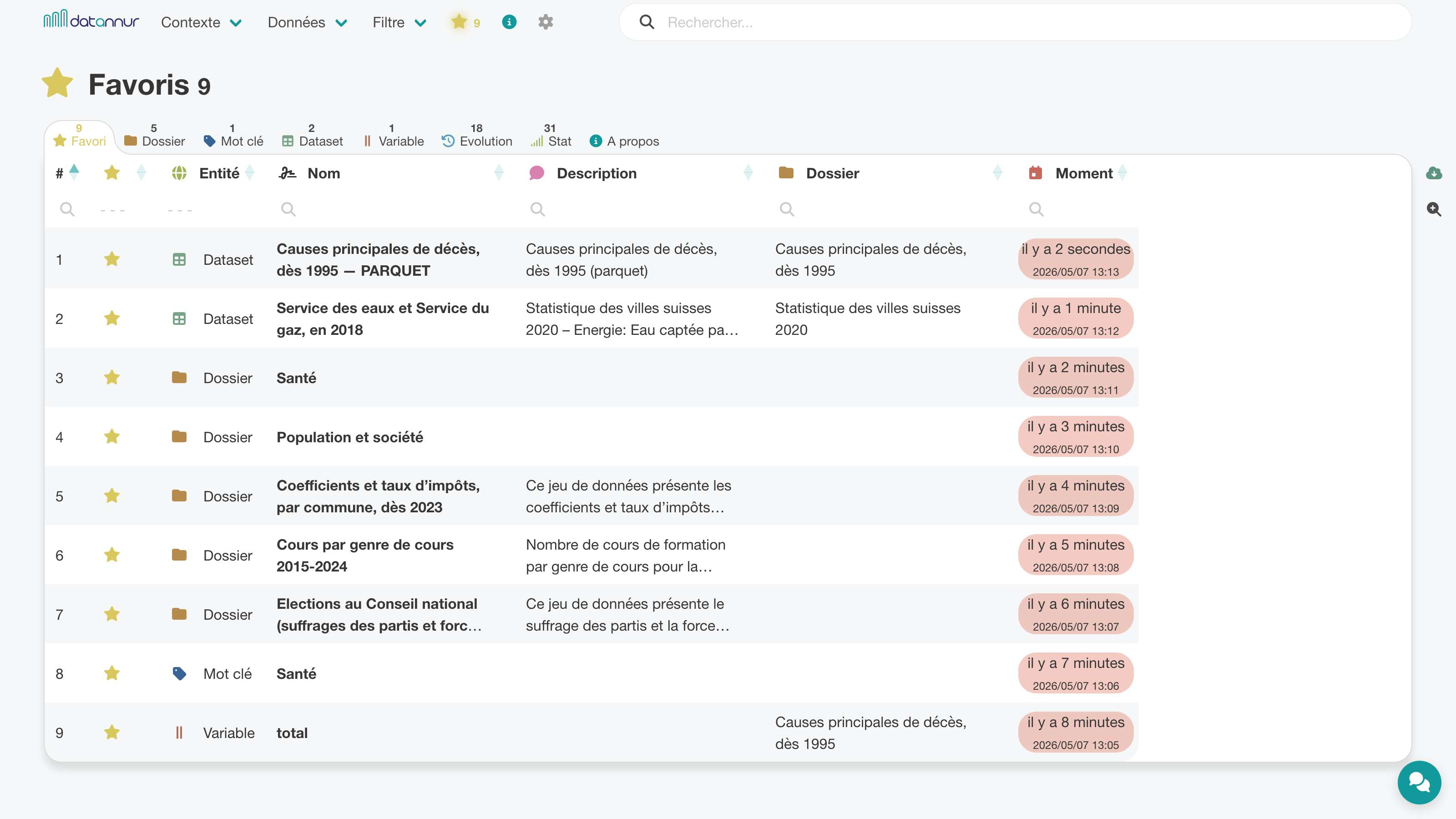
Tous les éléments du catalogue peuvent être ajoutés aux favoris en un clic. Une page dédiée permet ensuite de les retrouver en un même endroit, avec des onglets distincts selon le type d’élément.

Une page de configuration permet d’ajuster plusieurs aspects de l’interface, comme le mode sombre, le niveau d’arborescence affiché ou d’autres préférences visuelles. Elle permet aussi de réinitialiser les données d’utilisation stockées localement, comme les favoris, les recherches, les préférences ou les journaux.
Un onglet dédié regroupe par ailleurs les logs d’utilisation — pages consultées, recherches, favoris — ainsi qu’un résumé statistique permettant d’en visualiser les principaux usages.
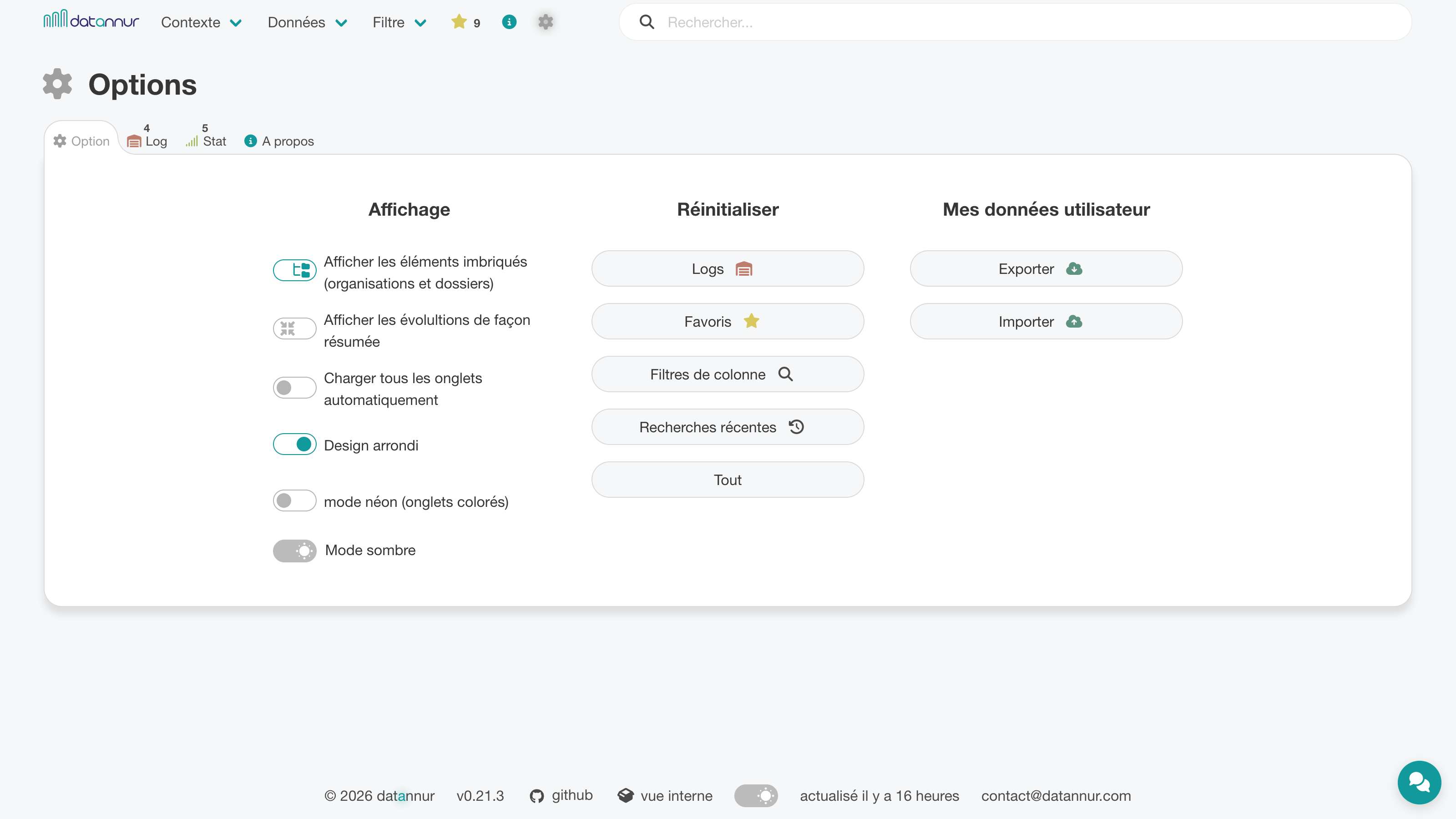
Les données d’utilisation stockées dans le navigateur peuvent être exportées ou importées à tout moment sous forme de fichier compressé (ZIP).
Les tableaux du catalogue peuvent également être exportés facilement, soit par copie dans le presse-papier, soit au format CSV ou Excel (XLSX).

datannur peut exposer les métadonnées du catalogue via une API REST et produire un export DCAT. Ces mécanismes permettent d’intégrer le catalogue à d’autres outils, d’alimenter des portails open data ou de réutiliser les métadonnées dans des chaînes de traitement existantes.
datannur intègre une vue interne qui permet d’explorer directement la structure de ses propres métadonnées. Le catalogue devient ainsi lisible de l’intérieur : on peut voir comment l’information est organisée, reliée et stockée.
Cette transparence aide à comprendre le fonctionnement de l’outil, à contrôler les structures internes et à s’approprier le catalogue dans les usages les plus avancés.